在数据分析与统计研究中,SPSS 作为全球领先的统计分析软件,其“加权个案”功能是处理非平衡数据、校正样本偏差的核心工具。然而,许多用户在初次接触该功能时,常对加权逻辑与操作路径存在困惑。本文将以总分总结构,从概念解析到实操指引,深入讲解SPSS 加权个案的意义、应用场景及具体操作步骤,并延伸相关高阶技巧,助力用户全面提升数据分析精度。
一、SPSS 加权个案是什么意思
加权个案(Weight Cases)是SPSS 中用于调整数据集中个案(即观测值)统计权重的功能。其核心目的是通过赋予不同个案差异化的权重值,使数据分析结果更贴近真实场景。以下是其核心应用场景与技术原理:
1.解决样本代表性偏差
在问卷调查或抽样调查中,若某些群体(如特定年龄段、职业类别)的样本量与实际分布不匹配,直接分析会导致结果失真。例如:
实际人口中女性占比60%,但样本中女性仅占40%。
通过SPSS 加权个案,为女性样本赋予1.5倍权重(60%/40%),男性赋予0.67倍权重(40%/60%),可校正统计结果。
2.处理重复测量数据
当同一被试者在不同时间点多次测量时,需通过加权避免重复计数。例如:
某患者在第1月、第3月、第6月分别进行检测,需将权重设为1/3,确保该个体在整体分析中仅等效为1个独立样本。
3.复杂抽样设计校正
在分层抽样、整群抽样等非简单随机抽样场景中,SPSS 加权个案可依据抽样概率调整权重,还原总体特征。
技术原理:权重值本质是一个乘数因子。假设某个案权重为2,在计算均值、方差等统计量时,该个案将被视为2个独立个案参与运算,但其原始数据值不变。
二、SPSS 加权个案在哪
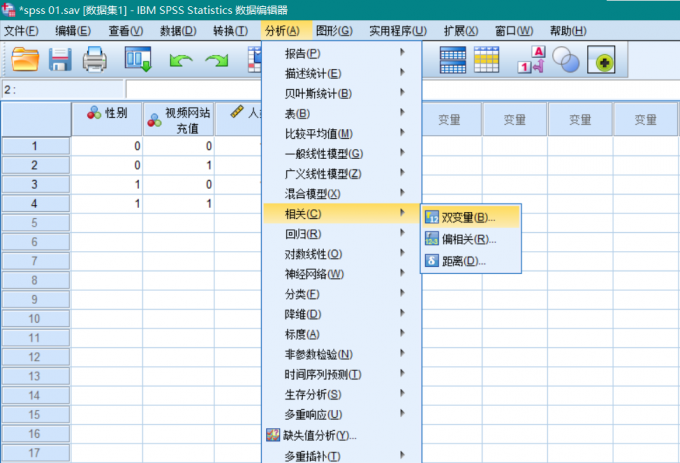
SPSS 加权个案功能的操作路径清晰,但需注意权重变量的选择与验证。以下是具体操作步骤及关键注意事项:
1.进入加权个案界面
打开SPSS 数据文件后,依次点击顶部菜单栏:
数据(Data)→加权个案(Weight Cases)
弹出对话框后,默认选项为“不对个案加权”(Donot weight cases),需手动切换为“加权个案”(Weight casesby)。
2.选择权重变量
从左侧变量列表中选择已准备好的权重变量(如“Weight”“样本权重”),拖拽至右侧“频率变量”(Frequency Variable)框内。
关键验证:权重变量必须为数值型(Numeric),且所有值≥0。若存在负数或缺失值,SPSS 将报错并中断加权。
3.应用加权与状态确认
点击“确定”后,SPSS 界面右下角状态栏会显示“权重开启”(WeightOn)提示。
可通过再次打开“加权个案”对话框查看当前是否处于加权状态,避免误操作。
注意事项:
加权仅影响后续分析(如描述统计、回归分析),不会修改原始数据。
完成分析后,务必返回“加权个案”界面选择“不对个案加权”,否则后续操作可能受残留权重干扰。
三、SPSS 加权个案后的数据分析验证方法
在应用加权个案后,需通过特定方法验证权重是否有效加载,并评估其对结果的影响。以下是SPSS 中的验证流程与对比策略:
1.加权前后描述统计对比
执行加权前,先对目标变量(如收入、满意度评分)进行频率分析或描述统计(分析→描述统计→频率/描述)。
应用加权后,重复相同分析,对比均值、标准差等指标的变化幅度。若差异显著,说明权重已生效。
2.交叉表加权效果检验
针对分类变量(如性别与购买意愿),分别生成加权前后的交叉表(分析→描述统计→交叉表)。
观察加权后单元格百分比的变化,例如:
加权前男性占比40%,加权后调整为50%,符合权重设定逻辑。
3.模型拟合度诊断
在回归分析中(如线性回归、逻辑回归),比较加权前后的模型R²、显著性水平(p值)等指标。
若加权后模型解释力提升且系数更符合理论预期,则证明加权策略有效。
避坑指南:
避免对已加权数据再次加权,否则会导致权重叠加,严重扭曲结果。
使用语法命令(如`WEIGHTBY WeightVar.`)时,需在日志文件中确认权重状态,防止静默错误。
SPSS 加权个案功能通过调整数据集中个案的统计权重,能够有效校正样本偏差、优化分析结果。从理解权重原理到实操路径,再到加权后的验证方法,用户需建立完整的操作闭环。建议在复杂项目中结合语法脚本(.sps文件)自动化执行加权与验证步骤,并通过交叉对比确保结果稳健性。掌握这些技能,将显著提升数据分析的可靠性与学术研究价值,充分发挥SPSS 在量化研究中的核心作用。
